
1. Consultando Dados – SELECT



Resumo: Neste tópico, você aprenderá como usar o comando SELECT da linguagem DML para recuperar dados de uma tabela no banco de dados.
É melhor dar do que receber? Quando se trata de Bancos de Dados, é possível que você precise recuperar seus dados, muito muitas vezes do que inseri-lo na base. Nessa tópico vamos conhecer o poderoso comando SELECT e saber como retornar as importantes informações que foram inseridas em suas tabelas.
A instrução SELECT da linguagem DML permite recuperar os dados a partir de uma ou mais tabelas do banco de dados. Está é a sintaxe simples da instrução SELECT:
SELECT coluna_lista
FROM tabela_lista
WHERE linha_condições
GROUP BY coluna_lista
HAVING grupo_condições
ORDER BY ordenar_lista ASC | DESCPrimeiro você tem que especificar o nome da tabela que você deseja recuperar os dados. O nome da tabela é antecedido pela comando FROM.
Segundo, você tem que indicar quais dados deseja recuperar. Você pode listar as colunas da tabela após o comando SELECT da linguagem DML.
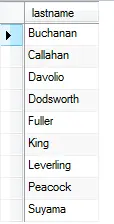
Suponha que você quer recuperar a coluna sobrenome (sobrenome) na tabela funcionarios, você pode executar a seguinte consulta:
SELECT Sobrenome FROM funcionariosA consulta busca os valores da coluna sobrenome (sobrenome) em todas as linhas da tabela funcionarios e retorna o resultado abaixo.
Você também pode usar o comando SELECT para recuperar várias colunas de uma tabela no banco de dados. Para fazer isso você deve colocar uma vírgula entre a lista de colunas. Ao especificar as colunas que queremos retornar os valores em nossa consulta, apenas os resultados que precisamos serão devolvidos.
Por exemplo, para retornar o primeito nome (Nome), sobrenome (sobrenome) e cargo (Titulo) de todos os funcionários, você pode executar a seguinte consulta:
SELECT sobrenome, Nome, Titulo FROM funcionarios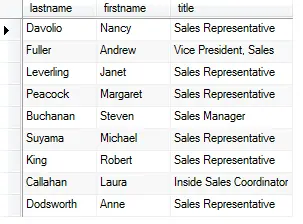
Selecionando colunas específicas você obtém resultados mais rápidos. Esta é uma boa prática de programação.

Para recuperar todas as informações (colunas) de uma tabela, você poderia listar todos os nome de colunas e separá-las por vírgulas. No caso de uma tabela com muitas colunas, você não vair querer listar todos eles, ao invés disso você pode usar um asterisco (*) para indicar que você deseja recuperar todas as colunas sem precisar explicitamente escrever a lista de colunas.
Por exemplo, a seguinte consulta permite recuperar todas as informações da tabela my_contacts usando o asterisco (*):

Veja o resultado do SELECT acima:

Você também pode usar SQL SELECT da linguagem DML para recuperar várias colunas de uma tabela do banco de dados. A fim de fazer isso você deve fornecer uma vírgula entre colunas na lista de coluna. Por exemplo, se você quiser recuperar o nome, sobrenome e título de todos os funcionários, você pode executar a seguinte consulta:
O SELECT * retorna todas as colunas da tabela.
Se precisássemos retornar apenas as pessoas que moram em Seattle, da maneira acima, precisaríamos ficar garimpando os dados. O que seria entediante e trabalhoso. Para isso usaremos a cláusula WHERE, vejamos a seguir.
Neste tutorial, você aprendeu como usar simples declaração SQL SELECT para recuperar dados de uma tabela. Você também aprendeu a selecionar uma única coluna, várias colunas, separando-os com uma vírgula, e todas as colunas usando o asterisco (*) a partir de uma tabela.
Tópicos relacionados
- WHERE
- Alias
- DISTINCT
- ORDER BY
- IN
- BETWEEN
- LIKE
- GROUP BY
- HAVING
2. Filtrar Consultas – WHERE
Resumo: Neste tópico, você aprenderá como usar o comando WHERE juntamente com o comando SELECT para filtrar os dados selecionados a partir de tabelas no banco de dados.
SELECT coluna_lista
FROM tabela_lista
WHERE linha_condição.A cláusula WHERE é usada com outras instruções SQL da linguagem DML, como as declarações SELECT , DELETE e UPDATE . Serve para filtrar registros nas tabelas para que satisfaçam as condições de linhas específicas. O SQL fornece vários operadores para permitir a construção de condições de linha (registros). Aqui estão os operadores mais comuns em SQL.
| Operador | Descrição |
|---|---|
| = | Igual |
| > | Maior que |
| < | Menor que |
| > = | Maior ou igual |
| <= | Menor ou igual |
| <> | Diferente |
| E | Operador lógico E |
| OU | Operador lógico OU |
A declaração do SELECT com a cláusula WHERE dá ao SGBD algo específico para ser pesquisado, com isso são retornados apenas as linhas que correspondem à condição. O sinal de igual (=) na cláusula WHERE é usado para testar se cada valor na coluna é igual a condição, se corresponder, a linha é retornada, caso não encontre nenhum registro, nenhuma linha é retornada.
Abaixo as linhas que foram retornadas por esta consulta, em que o primeiro nome é igual à Anne.
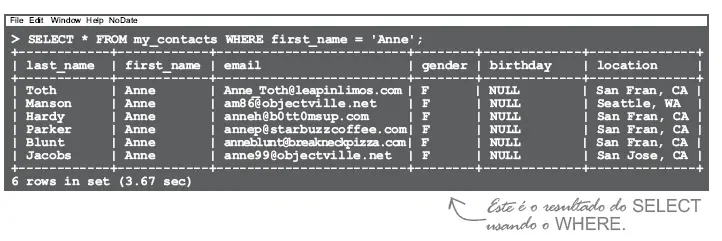
O comando SQL da linguagem DML primeiro busca todas as linhas da tabela de funcionarios através da cláusula FROM.
Depois o SQL elimina as linhas que não satisfazem a condição WHERE, neste caso as linhas que tem a coluna sobrenome (sobrenome) DIFERENTE de ‘King’.
Então o SQL elimina todas as colunas que não estão disponíveis na lista de colunas (só vai retornar as colunas sobrenome, Nome e Titulo).
SELECT sobrenome, Nome, Titulo
FROM funcionarios
WHERE sobrenome = 'King'sobrenome Nome Titulo
-------- --------- --------------------
King Robert Sales RepresentativePara localizar todos os funcionários que não vivem nos EUA na tabela funcionarios, você pode usar o operador DIFERENTE (<>) na cláusula WHERE da seguinte forma:
SELECT sobrenome, Nome, Titulo, Pais
FROM funcionarios
WHERE Pais <> 'USA'sobrenome Nome Titulo Pais
--------- --------- -------------------- -------
Buchanan Steven Sales Manager UK
Suyama Michael Sales Representative UK
King Robert Sales Representative UK
Dodsworth Anne Sales Representative UKPara localizar todos os funcionários que foram contratados antes de 1993, você pode usar MENOR QUE (<) como a seguir:
SELECT sobrenome, Nome, Titulo, Pais,DataAdmissao
FROM Funcionarios
WHERE DataAdmissao > '1993-01-01'sobrenome Nome Titulo Pais DataAdmissao
--------- --------- ------------------------ ------- --------------
Peacock Margaret Sales Representative USA 1993-05-03
Buchanan Steven Sales Manager UK 1993-10-17
Suyama Michael Sales Representative UK 1993-10-17
King Robert Sales Representative UK 1994-01-02
Callahan Laura Inside Sales Coordinator USA 1994-03-05
Dodsworth Anne Sales Representative UK 1994-11-15WHERE com operador AND
Os operadores lógicos OR e AND são usados para combinar várias condições na cláusula WHERE.
Várias condições podem ser unidas pelo operador AND e todas devem ser verdadeiras para retornar a condição como TRUE. Se uma das condições é falsa, toda a condição é avaliada como FALSE. Se uma das condições é desconhecida ou NULL toda a condição é avaliada como UNKNOWN (DESCONHECIDO).

Aqui está o resultado da consulta que trará os resultados que satisfaça as duas condições.
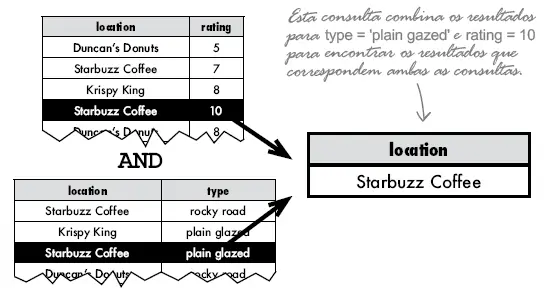
Suponha que você queira encontrar todos os funcionarios que foram contratados depois de 1993 e vivem nos USA, você pode usar o operador AND para combinar as duas condições como a seguinte consulta:
SELECT sobrenome, Nome, Titulo, Pais, DataAdmissao
FROM funcionarios
WHERE DataAdmissao > '1993-01-01' AND Pais = 'USA'sobrenome Nome Titulo Pais DataAdmissao
-------- --------- ------------------------ ------- --------------
Peacock Margaret Sales Representative USA 1993-05-03
Callahan Laura Inside Sales Coordinator USA 1994-03-05WHERE com o operador OR
Várias condições unidas pelo operador OR devem ser falsas para a condição inteira ser avaliada como FALSE. Se uma das condições é verdadeira, toda a condição é avaliada como TRUE. Se uma das condições é desconhecida ou NULL toda a condição é avaliada para desconhecida ou NULL.

Veja na tabela abaixo o resultado do SELECT acima, o resultado seria: KRYSPY KING e DUNCAN’S DONUTS .
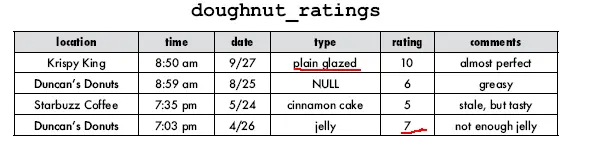
Por exemplo, você pode encontrar todos os funcionarios que vivem em Londres ou na cidade de Seattle, você pode usar o operador OR neste caso.
SELECT Nome, sobrenome, Cidade
FROM Funcionarios
WHERE Cidade = 'London' OR Cidade = 'Seattle'Nome sobrenome Cidade
--------- --------- -------
Nancy Davolio Seattle
Steven Buchanan London
Michael Suyama London
Robert King London
Laura Callahan Seattle
Anne Dodsworth LondonVeja mais alguns exemplos de AND e OR usando a tabela abaixo:
Resultados:


Neste tutorial, você aprendeu como filtrar os registros no conjunto de resultados na instrução SQL SELECT usando a cláusula SQL WHERE com condições. Você também aprendeu a usar vários operadores básicos comuns para a construção de uma condição e usar operadores lógicos para combinar condição juntos. Você ainda vai aprender como usar outro operador, como BETWEEN e IN para recuperar dados em um intervalo de valores e em um conjunto.
Tópicos relacionados
- SELECT
- Alias
- DISTINCT
- ORDER BY
- IN
- BETWEEN
- LIKE
- GROUP BY
- HAVING
3. Apelidos – ALIAS
Resumo: Neste tópico, você aprenderá como usar diferentes alias SQL incluindo alias de coluna e alias de tabela com a instrução SELECT .
Um Alias SQL é usado para organizar o resultado de uma consulta e evitar erros de ambiguidade nas tabelas pois várias tabelas podem possuir os mesmos nomes de colunas.
A linguagem SQL suporta dois tipos de alias (apelidos) que são conhecidos como alias de coluna e alias da tabela.
Alias de Coluna
Basicamente, quando você consulta dados de uma tabela no banco de dados, os títulos das colunas no resultado são os mesmo que o nome das colunas da tabela. No entanto, o nome da coluna (título) é na maioria das vezes, muito técnico e não lhe traz qualquer informação intuitiva, portanto, se você deseja alterar na saída da consulta o SQL fornece alias ou apelidos para permitir que você faça isso.
Vamos dar uma olhada em alguns exemplos do uso de alias de coluna para organizar o resultado de uma consulta.
SELECT NomeProduto AS product, PrecoUnitario AS price
FROM Produtos
WHERE PrecoUnitario >50
Na instrução SELECT acima, usamos dois aliases de coluna. O primeiro alias de coluna é product que representa a coluna NomeProduto e a segunda é price que representa a coluna PrecoUnitario.
Quando projetamos uma tabela de dados, muitas vezes descrevemos suas colunas como abreviações. Neste caso, o alias de coluna torna o resultado da consulta mais significativa e fácil de ler.
É importante notar que a palavra-chave AS é opcional. Você pode omitir a instrução AS e ter o mesmo resultado. Se o alias de coluna contém espaço, deve ser colocado entre aspas.
Podemos reescrever a consulta SELECT acima a seguir sem a instrução AS que o resultado será o mesmo:
SELECT NomeProduto product, PrecoUnitario "unit price"
FROM Produtos
WHERE PrecoUnitario > 50Alias de Tabela
Alias de tabela como seu nome indica é um novo nome da tabela para você se referenciar ao especificar suas colunas. O Alias de tabela é colocado após o nome da tabela na cláusula FROM da instrução SELECT. Você costuma usar alias de tabela quando se referir várias vezes a mesma tabela em uma instrução SELECT juntamente com a instrução JOIN ou quando o nome da tabela é muito grande, e você não quer perder tempo digitando seu nome várias vezes.
Por exemplo, você pode consultar a estrutura de uma organização para descobrir quem é o gerente de quem, usando a cláusula JOIN com alias de tabela da seguinte forma:
SELECT E.sobrenome 'Employee name', M.sobrenome 'Manager name'
FROM Funcionarios E
INNER JOIN Funcionarios M ON M.IDFuncionario = E.Reportase
Na consulta acima, nos referimos a mesma tabela empregados. Na cláusula FROM usamos E como alias de tabela para funcionarios e na cláusula INNER JOIN utilizamos M como alias de tabela gerente.
Quando você utiliza o alias (apelido) da tabela, a coluna da tabela tem de ser referida como a sintaxe abaixo para evitar erro de ambíguidade (mesmo nome de coluna em tabelas diferentes) de coluna.
tabela_alias.coluna_nome
SELECT E.sobrenome, M.sobrenome ...Alias é muito útil quando se usa com SUBQUERIES , JOINS e INNER JOIN.
Neste tutorial, você aprendeu como usar alias SQL incluindo alias de coluna e alias da tabela.
- Você usa alias de coluna para reorganizar ou reformatar os resultados para torna-lo mais significativo.
- Você usa alias de tabela quando você aborda uma tabela várias vezes em um único comando SELECT para torná-lo mais fácil de escrever e mante-lo mais curto.
Tópicos relacionados
- WHERE
- DISTINCT
- ORDER BY
- IN
- BETWEEN
- LIKE
- GROUP BY
- HAVING
4. Ocultar Duplicatas – DISTINCT
Resumo: Neste tópico, você aprenderá como usar o DISTINCT juntamente com o comando SELECT para eliminar registros duplicados.
O DISTINCT é utilizado para eliminar as linhas duplicadas no conjunto de resultados da instrução SELECT.
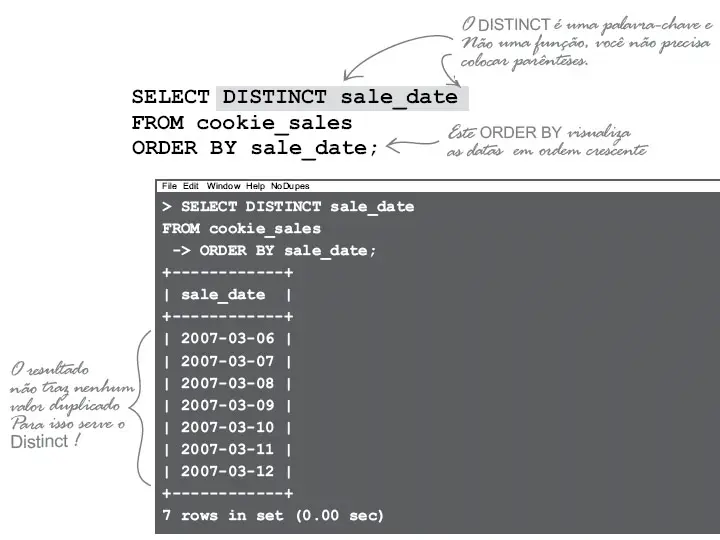
Por exemplo, para obter todas as cidades da tabela funcionarios você pode usar o SELECT como segue:
SELECT Cidade
FROM Funcionarios
Como você pode ver, os resultados das cidades estão duplicados. A informação das cidades duplicadas existem pois alguns funcionários vivem na mesma cidade.
Para remover as cidades duplicadas (registros duplicados), você pode usar o comando DISTINCT depois do comando SELECT como segue:
select distinct Cidade
from Funcionarios order by Cidade DESC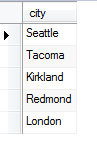
Agora, temos uma lista de cidades onde vivem os funcionarios sem valores duplicados.
É importante notar que o DISTINCT é utilizado antes do nome da coluna para filtrar valores duplicados de coluna. Neste caso, a cidade (city) é a coluna onde a restrição de duplicatas é efetuada.
Se colocar múltiplas colunas após o DISTINCT, a combinação dessas colunas serão utilizadas para avaliar os registros duplicados. Por exemplo, se você quer saber todas as cidades e países onde os trabalhadores vivem, você pode executar a seguinte consulta:
SELECT DISTINCT Cidade, Pais
FROM Funcionarios
Na consulta anterior, a combinação de cidade e país é utilizada para determinar a singularidade do registro no conjunto de resultados.
Neste tópico, você aprendeu como usar o comando DISTINCT na instrução SELECT para eliminar registros duplicados no conjunto de resultados.
Tópicos relacionados
- SELECT
- WHERE
- Alias
- ORDER BY
- IN
- BETWEEN
- LIKE
- GROUP BY
- HAVING
5. Ordenar Dados – ORDER BY
Resumo: Neste tópico, você aprenderá como usar o ORDER BY para classificar o resultado definido com base em critérios diferentes.
A instrução ORDER BY permite classificar o conjunto de resultados com base em um ou mais parâmetros de classificação em ordem crescente ou decrescente. Aqui está a sintaxe de do ORDER BY:
SELECT coluna1, coluna2…
FROM tabela_nome
ORDER BY coluna2 [ASC | DESC], coluna1 [ASC | DESC] …O ORDER BY só pode ser utilizado na instrução SELECT . A ordenação do ORDER BY deve ser classificável. Os tipos de dados podem ser carácter, numérico, data e hora.
Com o ORDER BY, você pode especificar a ordem de classificação, usando o comando ASC ( em ordem crescente) e DESC (em ordem decrescente). Se você não especificar a ordem de classificação, a ordenação padrão é crescente. Você pode classificar uma ou mais colunas em qualquer ordem que quiser.
Vamos dar uma olhada em alguns exemplos da utilização do ORDER BY.

No exemplo acima, a classificação do resultado é com base numa única coluna (Titulo). Você também pode classificar o resultado por várias colunas. Este recurso é conhecido como multi-classificação de colunas .
Por exemplo, você pode classificar uma coluna em ordem crescente e outra coluna em ordem decrescente.

O SQL define que a ordenação será por ordem das colunas, ou seja, primeiro irá ordenar a coluna Titulo de maneira ascendente (crescente). E então ordenará a coluna purchased de maneira decrescente dentro dos resultados obtido na primeira coluna.
O ORDER BY também pode aceitar expressões. Por exemplo, você pode usar a função de string CONCAT, que permite que você concatene várias seqüências em uma, para construir o nome completo de funcionarios, em seguida, ordenar pelo nome completo (alias – NomeCompleto) . A consulta a seguir ilustra a idéia:
SELECT sobrenome,',',Nome NomeCompleto
FROM Funcionarios
ORDER BY NomeCompleto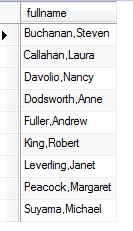
Quase todos SGBDs permitem que você especifique a classificação com base no número de posição da coluna na lista de seleção. A posição inicial da coluna na lista de seleção começa em 1, 2 e assim por diante … e esses números posicionais podem ser listados na cláusula ORDER BY.
Suponha que você queira classificar pela data de contratação do empregado (DataAdmissao), para descobrir quem são os colaboradores mais recentes na empresa; Você pode usar o número de posição na cláusula ORDER BY da seguinte forma:
SELECT sobrenome, Nome, DataAdmissao
FROM Funcionarios
ORDER BY 3 DESC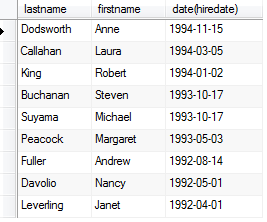
O resultado pela coluna DataAdmissao na lista de seleção é 3.
Como o número da posição é alterada quando você adiciona mais colunas na lista de seleção, você tem que mudar também no ORDER BY. Isso às vezes leva a um resultado inesperado se você se esquecer de mudar o número de posição. Portanto, não é recomendado o uso de número posicional na cláusula ORDER BY, você só deve usá-lo se não existir nenhuma outra opção.
Neste tópico, você aprendeu como usar ORDER BY para classificar o resultado em ordem crescente e decrescente.
Tópicos relacionados
- SELECT
- WHERE
- Alias
- DISTINCT
- IN
- BETWEEN
- LIKE
- GROUP BY
- HAVING
6. Filtrar Conjuntos – IN
Resumo: Neste tutorial, você aprenderá como usar o operador IN, juntamente com cláusula WHERE para recuperar dados em um conjunto de valores.
O operador IN permite determinar se um valor está contido em um conjunto de valores. A sintaxe de SQL usando o operador IN é a seguinte:
SELECT column_list
FROM table_name
WHERE column IN (value1, value2, value3…)
Use IN com um conjunto de valores entre parênteses, quando o valor que está na coluna coincidir com um dos valores no conjunto, a linha especificada ou colunas são retornadas.

É importante notar que o conjunto de valores deve ser delimitado por vírgulas e encerrado dentro de parênteses.
Por exemplo, para encontrar todos os produtos que têm preço unitário US$ 18, US$ 19 e US$ 20, você pode executar a seguinte consulta:
SELECT NomeProduto, PrecoUnitario
FROM Produtos
WHERE PrecoUnitario IN (18, 19, 20)
O IN ajuda a escrever múltiplos valores na cláusula WHERE. Você poderia utilizar o operador OR para reescrever a consulta acima da seguinte forma:
SELECT NomeProduto, PrecoUnitario
FROM Produtos
WHERE PrecoUnitario = 18 OR PrecoUnitario = 19 OR PrecoUnitario = 20Quando aumentarmos os valores, a consulta será mais complicada e difícil de ler. Então sempre que você escrever uma consulta que possuir vários operadores OR, lembre-se do operador IN para tornar a sua consulta mais fácil de ler e manter.
NOT IN
O operador IN pode se combinar com operador NOT. Para encontrar todos os registros cujo valor da coluna não está no conjunto você pode usar NOT IN.
O NOT IN lhe dará o resultado oposto do IN, ele retorna os valores que não estejam no conjunto de valores nos parênteses.

Por exemplo, você pode encontrar todos os produtos que têm preço unitário que não sejam 18 ou 19 ou 20, realizando a seguinte consulta:
SELECT NomeProduto, PrecoUnitario
FROM Produtos
WHERE PrecoUnitario NOT IN (18, 19, 20)A figura a seguir ilustra o trecho do resultado:

Além dos usos acima, o operador IN é usado também em subquerys (subconsultas) que você vai aprender mais adiante.
Neste tutorial, você aprendeu como usar o operador IN para encontrar dados que têm valor em um conjunto. Você também aprendeu a combinar com o operador NOT para consultar dados que não estejam no conjunto de valores.
Tutoriais relacionados
- SELECT
- WHERE
- Alias
- DISTINCT
- ORDER BY
- BETWEEN
- LIKE
- GROUP BY
- HAVING
7. Valores Nulos – IS NULL (nulo)
Resumo: neste tópico, você vai aprender um novo operador no SQL chamado IS para determinar se um valor é NULL ou não.
No mundo de banco de dados, NULL é desconhecido ou não aplicável ou falta de informação. Isso é diferente de um registro VAZIO. Por exemplo, as expressões A = NULL e B <> NULL não podem ser resolvidas por NULL por comparação.
Felizmente, o SQL fornece o operador IS para ajudar a determinar se um valor é nulo ou não.
a seguinte declaração ilustra a sintaxe de operador IS:
WHERE expression IS (NOT) NULL
Na sintaxe acima:
- Retorna valor booleano True se a expressão é NULL, caso contrário retorna FALSE.
- O operador IS é compatível com o Oracle , SQL Server, MySQL e plataformas PostgresSQL.
Exemplos:
Você pode usar o operador IS para verificar se um fornecedor não tem fax, para que você possa se comunicar com eles usando diferentes canais de comunicação.
Aqui está a consulta para fazer isso:
SELECT NomeCompanhia, fax
FROM fornecedor
WHERE fax IS NULLPara imprimir a lista de fax de nossos fornecedores podemos usar o operador IS NOT da seguinte forma:
SELECT NomeCompanhia, fax
FROM Fornecedores
WHERE fax IS NOT NULLO operador IS pode ser aplicado em todos os casos que se necessita verificar se um valor é NULL (nulo) ou NOT NULL (não nulo).
Neste tópicol, você aprendeu como usar o operador IS para determinar se um valor é NULL ou NOT NULL.
Tópicos relacionados
- IN
- BETWEEN
- LIKE
8. Filtrar Intervalos – BETWEEN
Resumo: Neste tópico, você aprenderá como usar o operador BETWEEN na cláusula WHERE para consultar os registros que têm valores em um intervalo de valores.
O operador BETWEEN permite recuperar os registros que têm valores em um intervalo de valores.
A sintaxe do BETWEEN é a seguinte:
SELECT coluna_lista
FROM tabela_nome
WHERE coluna BETWEEN menor_valor AND maior_valorNa consulta anterior, o SQL vai lhe dar todos os registros que o valor da coluna na cláusula WHERE entre menor_valor e maior_valor
O between é equivalente a usarmos o sinal de <= e => , mas não é a mesma coisa usar < e >. O between retorna os valores iguais também, lembre disso.
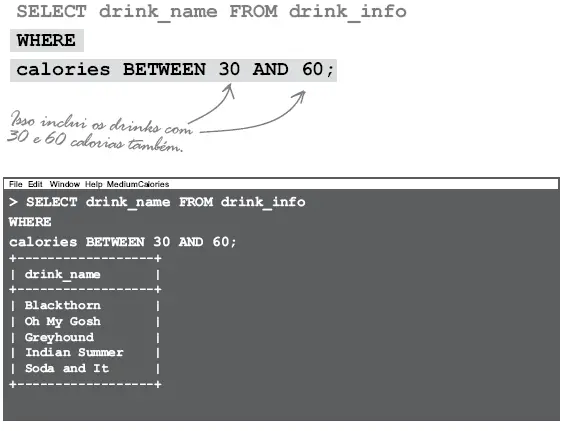
Por exemplo,se você deseja recuperar produtos que têm preço unitário (PrecoUnitario) de US$ 18 a US$ 19, você pode usar o operador BETWEEN como a seguinte consulta:
SELECT NomeProduto, PrecoUnitario
FROM Produtos
WHERE PrecoUnitario BETWEEN 18 AND 19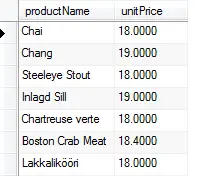
É possível ter o mesmo resultado do BETWEEN utilizando os operadores menor ou igual (<=) e maior ou igual (> =) operadores como se segue:
SELECT NomeProduto, PrecoUnitario
FROM Produtos
WHERE PrecoUnitario >= 18 AND PrecoUnitario <= 19Da mesma maneira que o operador IN, o operador BETWEEN pode se combinar com operador NOT para encontrar registros que não têm valores em um determinado intervalo.
Por exemplo, para encontrar todos os produtos que não têm preço unitário entre US$ 18 e US$ 19, você pode combinar o operador NOT com o operador BETWEEN. Aqui está a consulta:
SELECT NomeProduto, PrecoUnitario
FROM Produtos
WHERE PrecoUnitario NOT BETWEEN 18 AND 19
Neste tópico você aprendeu como usar o operador BETWEEN para encontrar registros que estão em um intervalo de valores. Além disso você também aprendeu como combinar o operador NOT com o operador BETWEEN para encontrar todos os registros fora de um intervalo de valores.
Tutoriais relacionados
- SELECT
- WHERE
- Alias
- DISTINCT
- ORDER BY
- IN>
- LIKE
- GROUP BY
- HAVING
9. Filtrar Padrões – LIKE
Resumo: Neste tópico, você aprenderá como usar o LIKE na consulta de dados com base no casamento de padrões.
A instrução LIKE permite que você execute uma cadeia de pesquisa de texto com base em padrões. A declaração LIKE é usada na cláusula WHERE de quaisquer declarações SQL válidas como SELECT, INSERT, UPDATE e DELETE.
O SQL fornece-lhe dois carácteres coringa para a construção de um padrão. Eles são porcentagem (%) e underline ( _ ).
- porcentagem (%) permite combinar uma seqüência de carácteres, incluindo espaços.

- underline ( _ ) permite corresponder a qualquer caráctere único.

A sintaxe do operador LIKE utilizado com instrução SELECT é a seguinte:
SELECT coluna1, coluna2…
FROM tabela_nome
WHERE coluna LIKE padrao
O tipo de dados da coluna deve ser alfanumérico para usar o LIKE. Poderia ser o tipo de dados CHAR, VARCHAR, NVARCHAR…
Vamos dar uma olhada em alguns exemplos da utilização do LIKE e a construção de padrões.
Suponha que você queira encontrar todos os funcionarios com o sobrenome começando com carácter D, você pode executar a seguinte consulta.
SELECT sobrenome, Nome
FROM funcionarios
WHERE sobrenome LIKE 'D%'
A expressão ‘D%’ significa encontrar todos os registro onde lastanme comece com ‘D’ e seguido por quaisquer carácteres.
Para encontrar todos os funcionários que têm o primeiro nome que termina com carácter ‘t’, você pode executar a seguinte consulta.
SELECT sobrenome, Nome
FROM funcionarios
WHERE Nome LIKE '%t'
A expressão ‘% t “significa qualquer string em qualquer comprimento e terminando com o carácter ‘ t ‘.
Você pode colocar o ‘%’ coringa no início e no fim de uma seqüência para localizar qualquer string dentro desses coringas. Por exemplo, para localizar todos os funcionários que têm o sobrenome contendo a string “ll”, você pode executar a seguinte consulta da seguinte forma:
SELECT sobrenome, Nome
FROM funcionarios
WHERE sobrenome LIKE '%ll%'
Os dois coringas ‘%’ e ‘_’ podem se combinar juntos para construir um padrão. Por exemplo, você pode encontrar todos os funcionários que têm o sobrenome começando com quaisquer carácteres únicos, seguidos pelo carácter ‘a’ e seguido por quaisquer carácteres. Você pode usar a combinação de ambos os carácteres coringa. Aqui está a consulta para fazer isso:
SELECT sobrenome, Nome
FROM Funcionarios
WHERE sobrenome LIKE '_a%'
A declaração LIKE também pode se combinar com o operador NOT para encontrar toda a cadeia, que não corresponde ao padrão. Por exemplo, se você quiser encontrar todos os funcionários onde o primeiro nome não comece com o carácter ‘D’, você pode executar a seguinte consulta:
SELECT sobrenome,Nome
FROM funcionarios
WHERE sobrenome NOT LIKE 'D%'Neste tópico, você aprendeu como usar o LIKE para encontrar seqüências de texto que correspondem a um padrão. Você aprendeu como usar os dois carácteres coringa: porcentagem (%) e underline ( _ ) para a construção de um padrão.
Tópicos relacionados
- SELECT
- WHERE
- Alias
- DISTINCT
- ORDER BY
- IN
- BETWEEN
- GROUP BY
- HAVING
10. Agrupar Conjuntos – GROUP BY
Resumo: Neste tópico, você aprenderá como a cláusula GROUP BY agrupa um conjunto de resultados com base em um grupo de colunas.
O GROUP BY é usado para dividir um conjunto de resultados retornados de uma instrução SELECT em grupos baseados em grupos de colunas. Para cada grupo você pode aplicar funções agregadas, como SUM, AVG, MIN, MAX e COUNT para emitir um resumo das informações.
A função GROUP BY usada juntamente com a função SUM soma os valores da coluna agrupando a soma por grupos de valores.
O GROUP BY é muito útil quando você quer analisar os dados de forma analítica como quantas ordens de venda foram emitidas por um cliente e vendidas por determinado vendedor. Ele é frequentemente usado no sistema de datawarehouse ou BI para produzir relatórios analíticos.
Funções de Agregação
A Função SUM pode efetuar operações sobre um, ou vários valores, podemos somar todos os valores de uma coluna usando essa função. Ela somará todos os valores da coluna que estiver dentro do parêntesis.
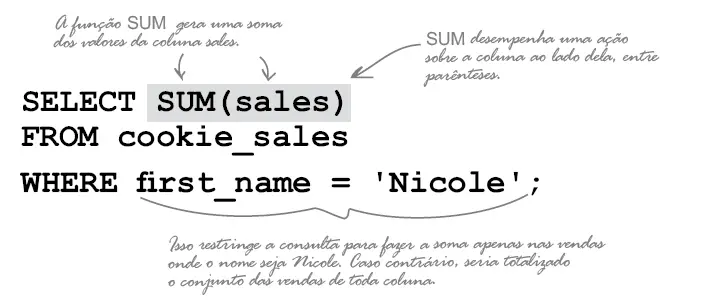


Outras funções:
AVG – Esta função soma todos os valores agrupados e divide pelo número de valores achados.
MIN e MAX– Estas funções retornam o Menor e Maior valor respectivamente encontrados.
COUNT – Retorna o número de linhas encontradas.
A sintaxe simples do GROUP BY é a seguinte:
SELECT c1,c2,... cn, função_agregação(expressão)
FROM tabelas WHERE condição
GROUP BY c1, c2, ... cn
ORDER BY ordem_colunas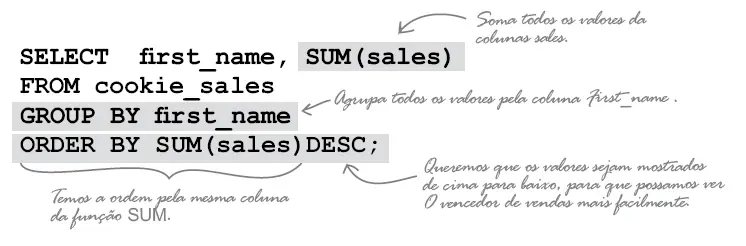
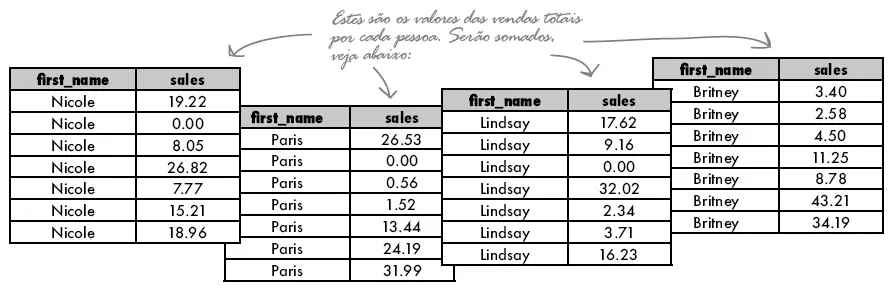
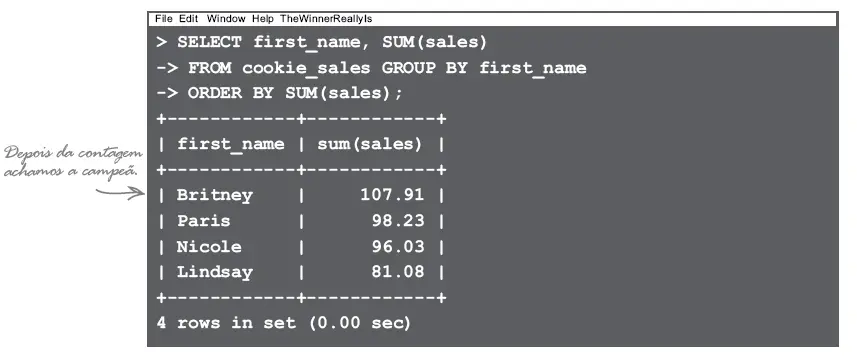
Vamos dar uma olhada em outros exemplos do uso do GROUP BY para ver como ele funciona. Vamos usar a tabela Ordens_Detalhes.
Cada ordem de venda é identificada por um ID único que é uma chave primária. Os itens que vendemos são armazenados em uma tabela chamada Ordens_Detalhes. Para obter receita de venda com base em cada ordem de venda podemos usar GROUP BY com função SUM como segue:
SELECT IDOrdem, SUM(PrecoUnitario * Quantidade) AS total
FROM Ordens_Detalhes
GROUP BY IDOrdemAqui está um trecho do resultado:
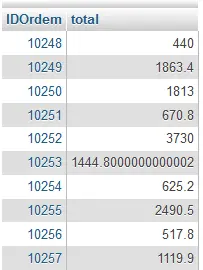
Na consulta anterior, primeiro o SQL olha para a cláusula GROUP BY e grupos do conjunto de resultados em grupos com base na identidade da ordem. Então o SQL calcula o total de coluna preçoUnitário múltiplo com coluna de quantidade para cada grupo.
Você pode usar GROUP BY sem as funções de agregação. Neste caso, o GROUP BY funciona como DISTINCT.
O GROUP BY é geralmente usado com a cláusula ORDER BY para classificar o conjunto de resultados.
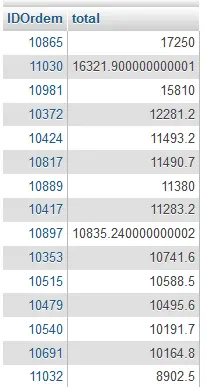
Por exemplo, você pode classificar a venda total de cada ordem de venda, em ordem decrescente como a seguinte consulta:
SELECT IDOrdem, SUM(PrecoUnitario * Quantidade) total
FROM Ordens_Detalhes
GROUP BY IDOrdem
ORDER BY total DESCAqui está o trecho do resultado da consulta acima:
Smartwatch Redmi watch 3 active relógio Redmi Xiaomi preto
Xiaomi Mi Smart Band 6 - 2021 - Versão Chinesa - Tela Amoled 1,56''
Xiaomi Mi Band 8 Active versão global (Preto)
Agrupando por várias colunas com GROUP BY
Você pode agrupar o resultado não apenas por uma coluna, mas também por várias colunas.
Por exemplo, se você quer saber quantas ordens de venda foram emitidas por um cliente e qual o vendedor, você pode agrupar o resultado com base no cliente e no funcionário.
O diagrama relacional das tabelas envolvidas segue abaixo:
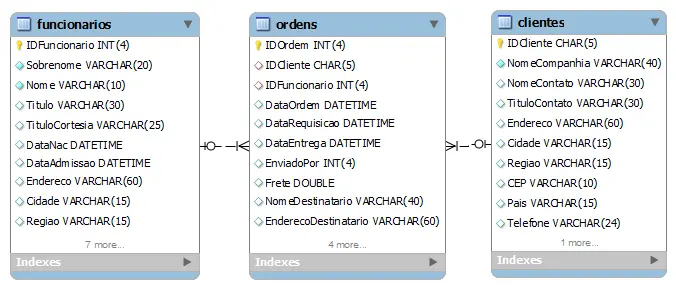
A seguir a consulta:
SELECT b.idcliente,
b.NomeCompanhia,
a.IDFuncionario AS "Vendedor ID",
concat(e.sobrenome,e.Nome) as "Vendedor",
COUNT(a.IDOrdem) AS "Numero de Ordens"
FROM Ordens a
INNER JOIN Clientes b ON a.idcliente = b.idcliente
INNER JOIN Funcionarios e ON e.IDFuncionario = a.IDFuncionario
GROUP BY b.idcliente,
a.IDFuncionario
ORDER BY b.idcliente asc, "Numero de Ordens" descAqui está o trecho de dados retornado pela consulta acima:
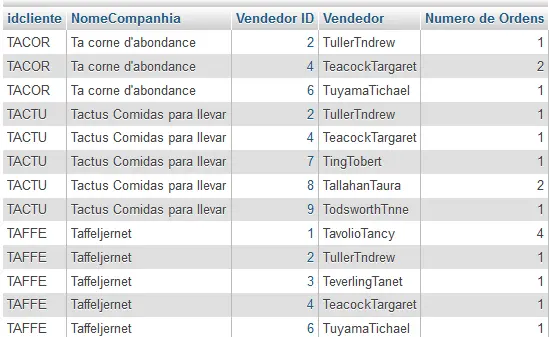
Neste tópico, você aprendeu como usar o GROUP BY para dividir os registros em um conjunto de resultados de grupos e aplicar a função agregada SUM para cada grupo. O GROUP BY é geralmente usado com HAVING que vamos mostrar adiante.
Tópicos relacionados
- SELECT
- WHERE
- Alias
- DISTINCT
- ORDER BY
- IN
- BETWEEN
- LIKE
- HAVING
11. Filtrar Grupos de Conjuntos – HAVING
Resumo: Neste tópico, você aprenderá como utilizar a cláusula HAVING para adicionar condições para grupos de registros retornados em um GROUP BY.
A cláusula HAVING foi adicionada ao SQL porque a palavra-chave WHERE não poderia ser usada com funções de agregação.
A cláusula HAVING é utilizada juntamente com a cláusula GROUP BY para filtrar grupos de registros com base em certas condições. O HAVING é semelhante a cláusula WHERE em termos de funcionalidade. A cláusula WHERE filtra os registros enquanto a cláusula HAVING filtra grupo de registros.
Vamos dar uma olhada em alguns exemplos do uso do HAVING para ter uma compreensão melhor.
Se você quiser encontrar todas as ordens de venda que têm venda total mais de US $ 12.000, você pode usar HAVING em conjunto com a cláusula GROUP BY.
SELECT IDOrdem, SUM(PrecoUnitario * Quantidade) Total
FROM Ordens_Detalhes GROUP BY IDOrdem
HAVING total > 12000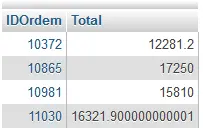
Suponha que você queira encontrar todos os pedidos que tenham mais de 5 produtos vendidos, você pode usar a função COUNT em conjunto com HAVING e o GROUP BY.
Segue a consulta:
SELECT IDOrdem, COUNT(IDProduto) produto_contador
FROM Ordens_Detalhes
GROUP BY IDOrdem
HAVING produto_contador > 5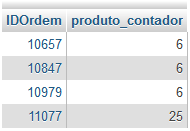
LIMIT
Limitando o número de resultados na consulta

Ex: Suponha que você tenha uma lista de 1000 músicas atuais tocando em estações de rádio, mas você quer listar apenas as “top 100” em ordem de popularidade. O LIMIT vai permitir que você veja apenas as 100, e não as outras 900 canções.

O LIMIT nos permite identificar “blocos” dentro da consulta. Para isso, podemos usar LIMIT com dois parâmetros como acima.
Lembre do “top 100” de músicas. Suponha que gostaríamos de ver 20 músicas a partir da 30ª. Adicionando um parâmetro extra para o LIMIT isso resolveria o problema.
EX: LIMIT 19, 10. O 19 diz para começar pelo 20ª registro, lembre-se que o SQL conta a partir do 0, e o parâmetro 10 diz para nos retornar 10 linhas(registros).
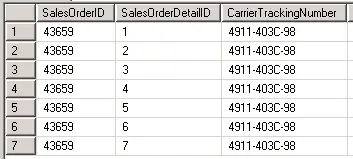
O LIMIT No MS SQL Server NÃO EXISTE, use o TOP
Exemplo 1, retornando os primeiros 7 registros:SELECT TOP 7 * FROM sales.salesorderdetail
Neste tópico, você aprendeu como usar a cláusula HAVING para filtrar os registros retornados pelo GROUP BY. Também aprendeu a limitar os resultados com o TOP e LIMIT.
Tópicos relacionados
- SELECT
- WHERE
- Alias
- DISTINCT
- ORDER BY
- IN
- BETWEEN
- LIKE
- GROUP BY
12. Inserir Dados – INSERT
Resumo: Neste tópico, você aprenderá como inserir um ou mais registros em uma tabela no banco de dados através da cláusula INSERT. Além disso o INSERT também permite copiar dados de uma tabela para outra.
O INSERT é muitas vezes chamado de INSERT INTO.
Aqui está a sintaxe do INSERT que permite inserir um registro de cada vez em uma tabela de banco de dados.
INSERT INTO nome_tabela (coluna1, coluna2…)
VALUES (valor1, valor2,…).O número de colunas (coluna1, coluna2, …) e os valores (valor1, valor2, ..) devem ser o mesmo. Se os nomes das colunas for omitido, o valor padrão para a coluna é utilizado. Os valores inseridos também devem satisfazer outras condições, como restrições de chave estrangeira, não nulos … caso contrário, a ação de inserção vai falhar e o novo registro não será adicionado à tabela.
Insira um registro em uma tabela.
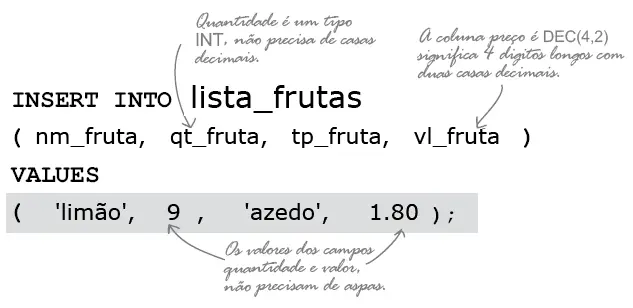
O comando faz o que seu próprio nome diz, insere dados. Dê uma olhada no comando abaixo para ver como funciona cada parte. Os valores no segundo parênteses devem estar na mesma ordem das colunas (primeiro parênteses).

Aqui um exemplo de comando real.

Na declaração abaixo repare nas colunas quantidade de frutas (qt_frutas) e valor da fruta (vl_fruta), os valores não são do tipo texto, correspondem a inteiro INT e decimal DEC(4,2) e não necessitam de aspas simples.
Vamos dar uma olhada em um exemplo de inserção de dados na tabela Transportadoras usando instrução INSERT.
INSERT INTO Transportadoras (NomeCompanhia, Telefone)
VALUES ('Aliança Transportadora','1-800-222-0451')A coluna IDTransportadora é a chave primária da tabela Transportadoras e é automaticamente incrementado (auto_incremento) cada vez que for inserido um novo registro, de modo que não precisamos lista-lona lista de colunas. Apenas os dados nome da empresa e telefone que vamos passar para a instrução INSERT. Depois de executar a consulta, o servidor de banco de dados retorna o número da linha afetada. Aqui você tem uma linha afetada, indicando que uma linha foi adicionada com sucesso a tabela.
Variações do Comando INSERT
Mudando a ordem das colunas – Você pode alterar a ordem das colunas no comando insert, porém os valores deverão seguir a mesma ordem das colunas!

Omitindo nome das colunas – Você pode suprimir os nomes das colunas, porém nesse caso, todos os valores correspondentes a todas as colunas dos banco de dados devem ser declarados e na mesma ordem que constam na tabela.

Inserindo apenas algumas colunas – Você pode inserir apenas algumas colunas e deixar outras de fora.

Inserir vários registros em uma tabela
O INSERT também permite que você inserira vários registros em uma tabela de cada vez. Aqui está a sintaxe:
INSERT INTO nome_tabela(coluna1,coluna2…)
VALUES (valor1,valor2,…),(valor1,valor2,…), …Desta forma, você fornece vários valores que são correspondentes à lista de colunas da tabela. Abaixo um exemplo de inserção de vários registros na tabela Transportadoras.
INSERT INTO Transportadoras(NomeCompanhia,Telefone)
VALUES ('FEDEX','1-800-782-7892'),
('CORREIO','1-800-225-5345')Copiar dados de outra tabela
Às vezes você precisa copiar dados de uma tabela para outra tabela para fazer um backup, por exemplo. O INSERT permite copiar os dados de uma tabela para uma outra tabela no banco de dados. Aqui está a sintaxe:
INSERT INTO nome_tabela(coluna1, coluna2,…)
SELECT valor1, valor2… FROM nome_tabela2 …A lista de seleção deve ser correspondente as colunas da tabela para onde você deseja copiar os dados.
Suponha que você tenha uma tabela temporária chamada Transportadoras_tmp cuja estrutura é exatamente a mesma que a tabela transportadoras. Agora você deseja copiar os dados da tabela transportadoras para a tabela temporária, você pode usar INSERT INTO SELECT. Neste caso, realizando a consulta seguinte:
INSERT INTO Transportadoras_tmp (NomeCompanhia, Telefone)
SELECT NomeCompanhia, Telefone FROM TransportadorasNeste tópico, você aprendeu como usar o INSERT para inserir um ou mais registros em uma tabela. Além disso, você também aprendeu a copiar os dados de uma tabela para outra usando o INSERT SELECT INTO.
Tutoriais relacionados
- UPDATE
- DELETE
13. Editar Dados – UPDATE
UPDATE permite modificar dados em uma tabela no banco de dados. Com o UPDATE, você pode modificar os dados de toda a tabela ou um subconjunto de dados com base na condição da cláusula WHERE.
Até agora você aprendeu a inserir e consultar seus dados. Agora aprenderemos a alterar os registros de nossa tabela. Vamos aprender a alterar um conjunto ou apenas uma linha de registros. O UPDATE atualiza uma coluna, ou colunas, com um novo valor. E, assim como o SELECT, você pode utilizar a cláusula WHERE para indicar qual a linha que deseja editar.

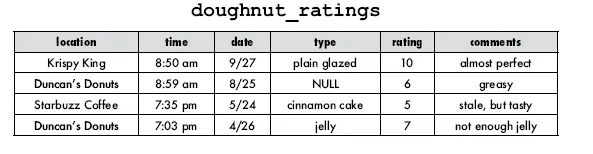
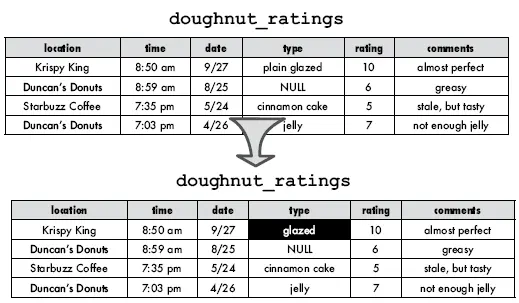
A palavra SET informa ao SGBD que é preciso mudar uma coluna, ela deve vir antes do sinal de igual que contém o valor a ser alterado.
No caso acima, estamos mudando a string “plain glazed’ para apenas “glazed” A cláusula WHERE diz que somente na coluna onde a string “plain glazed” for encontrada a alteração deve ser efetuada, ou seja, substituir por “glazed”.
Veja como ficou a alteração com o select acima:
Quando você usa o UPDATE, você não está apagando nada, em vez disso, você está reciclando um registro velho para um novo registro.
Aqui está a sintaxe típica de UPDATE:
UPDATE tabela_nome
SET coluna1 = valor1 , coluna2 = valor2
WHERE condiçãoPrimeiro você especifica uma tabela onde você deseja atualizar os dados após A palavra UPDATE. Você pode atualizar os dados em uma coluna ou mais colunas, as colunas tem de ser separadas por vírgulas (,).
Não é obrigado fornecer os dados diretamente para a instrução UPDATE. Pode-se usar os dados recuperarados de outra tabela e, em seguida, usá-los para no UDPATE. Os dados que você obter a partir de uma instrução SELECT, certifique-se que essa consulta deve retornar um único tipo de registro, compatível com a coluna que você deseja atualizar.
CUIDADO: A cláusula WHERE é opcional. Se você omitir a cláusula WHERE, todos os registros da tabela serão atualizado.
Vamos olhar alguns exemplos da utilização do UPDATE.
Suponha que um dos funcionários da empresa se case e precise mudar seu sobrenome, então você tem que fazer a mudança usando a instrução UPDATE. Aqui está a consulta para fazer isso:
UPDATE Funcionarios
SET Sobrenome = 'Phan'
WHERE IDFuncionario = 3.Suponha que a identificação do funcionário é 3.
Outro exemplo é um dos funcionários da empresa alterar o endereço e você deseja atualizar as informações de endereço, incluindo cidade, região e CEP. Neste caso, você pode usar UPDATE para alterar esses dados.
UPDATE Funcionarios
SET Endereco = '1300 Carter St', Cidade = 'San Jose', Cep = 95125, regiao = 'CA'
WHERE IDFuncionario = 3
Operações Matemáticas no UPDATE
No SQL podemos realizar operações matemáticas com os valores das colunas do tipo INT. Podemos adicionar um novo valor somando a ele mesmo.
Veja o exemplo abaixo:

UPDATE com a expressão CASE
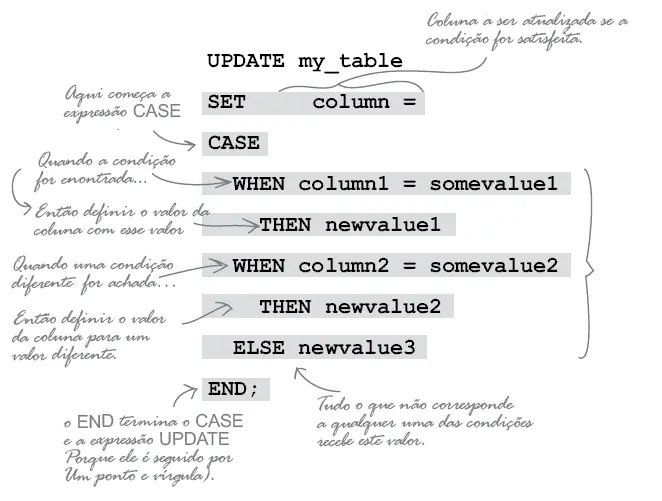
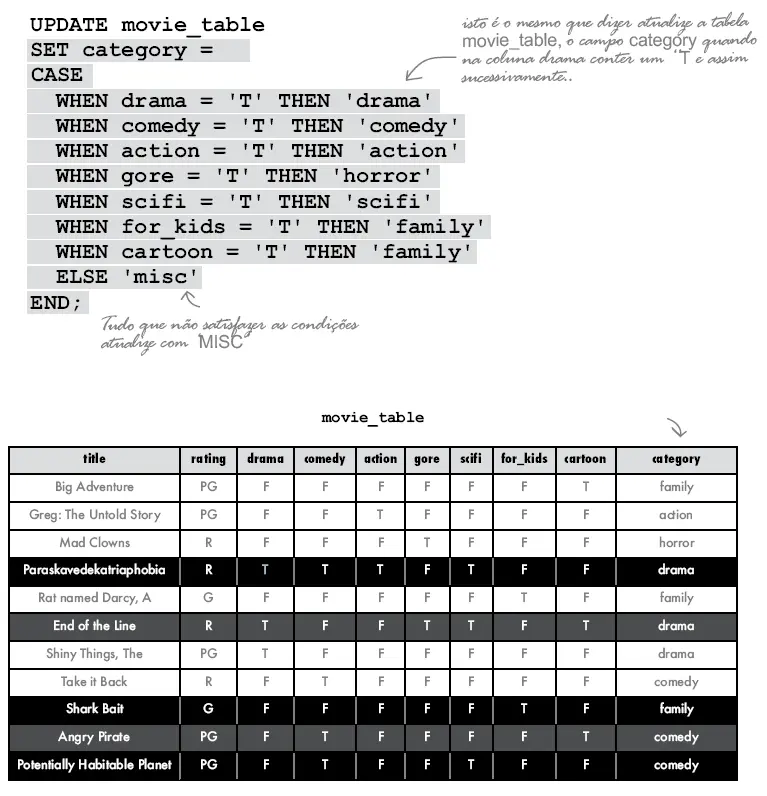
Com a expressão CASE podemos atualizar várias colunas ao mesmo tempo. Confrontando o valor da coluna contra uma condição, se a condição for atendida a coluna é preenchida com um valor determinado. Ele ainda permite que você diga ao SGBD que se qualquer registro não atender a condição preenchemos com um outro valor.
Veja o exemplo abaixo:
Você também pode usar o UPDATE juntamente com a função UPPER() para mudar todos os textos de sua tabela para texto em maiúsculo, ou usar a função LOWER() para deixar o texto todo em minúscula.
Neste tópico, você aprendeu como usar a instrução UPDATE para atualizar dados em uma tabela no banco de dados.
Tutoriais relacionados
- INSERT
- DELETE
14. Apagar Dados – DELETE
Resumo: Neste tópico, você aprenderá a usar o DELETE para remover os dados de tabelas.
O DELETE permite excluir um ou mais registros em uma tabela no banco de dados. A sintaxe da instrução DELETE é a seguinte:
DELETE FROM tabela_nome
WHERE condiçãoO DELETE é o comando para apagar linhas de dados da sua tabela. Ele também usa a cláusula WHERE que você já viu, ele faz exatamente o que se propõe, apaga todos os registros que correspondem à condição de sua cláusula.
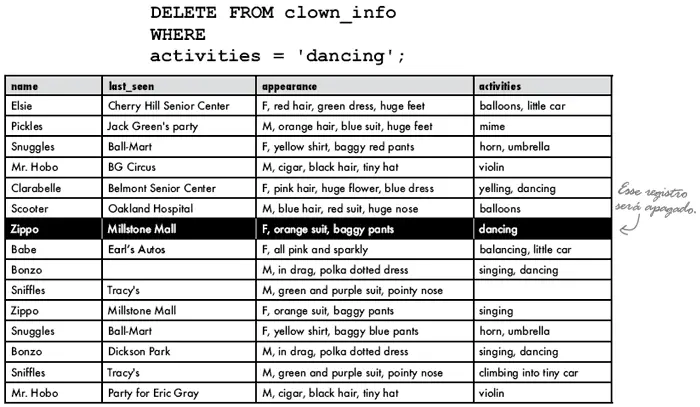
CUIDADO: Se você omitir a cláusula WHERE da instrução DELETE, ele irá apagar todos os registros na tabela de banco de dados.
É muito demorado e menos eficiente usar DELETE para excluir uma grande quantidade de dados. Se você deseja apagar todos os dados de uma tabela, o SQL fornece o comando TRUNCATE que é mais eficiente para apagar toda uma tabela.
Vamos olhar alguns exemplos de uso do DELETE.
Se você deseja remover o funcionário número três da tabela Funcionarios, basta executar a seguinte consulta:
DELETE FROM Funcionarios
WHERE IDFuncionario = 3Se algum funcionarios na tabela possuir registro com IDFuncionario igual a 3, ele será excluído de outra forma não acontece nada.
Para apagar todos os registros da tabela Funcionarios (não recomendado, faça um backup antes de fazer isso), você apenas executa a seguinte consulta:
DELETE FROM FuncionariosO DELETE torna-se mais complicado quando você precisa excluir um registro de uma tabela que tem relacionamento com outras tabelas.
Por exemplo, cada empregado trabalha em um ou mais territórios. A tabela Funcionarios_Territorios é usada para armazenar o mapeamento entre empregado e seu território.
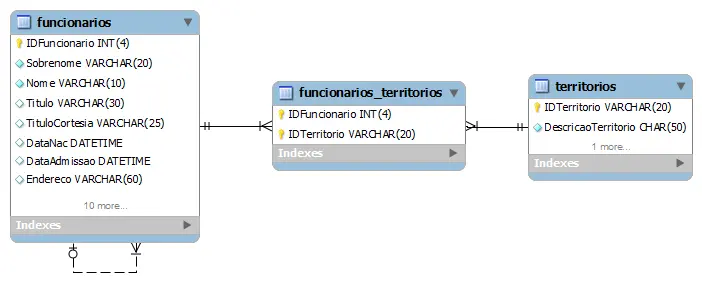
Quando você TENTA excluir um registro de funcionário da tabela Funcionarios, você também deve PRIMEIRO excluir os registros que se relacionam entre Funcionarios_territórios. Para fazer isso você tem que executar duas instruções DELETE na ordem que se segue:
DELETE FROM Funcionarios_Territorios
WHERE IDFuncionario = 3
DELETE FROM Funcionarios
WHERE IDFuncionario = 3;Quase todos os SGBDs permitem que você crie uma constraint chamado integridade referencial entre duas tabelas vinculadas. Portanto, se um registro em uma tabela for excluído, os outros registros nas tabelas vinculadas, se existirem, são eliminados também. Portanto, neste caso você só só tem que executar apenas um DELETE para que os dados sejam consistentes.
Neste tópico, você aprendeu como usar o DELETE para excluir um ou mais registros em uma tabela. Você também aprendeu sobre restrições de integridade referencial entre as tabelas para que você possa excluir registros automaticamente em tabelas vinculadas.
NÃO ESQUEÇA AS REGRAS DO DELETE
- Você não pode usar o DELETE para excluir o valor de uma única coluna ou de todas das colunas.
- Você pode usar o DELETE para apagar uma única linha ou várias linhas (registros), Dependendo da cláusula WHERE.
- Podemos usar WHERE, LIKE, IN, BETWEEN etc. com o DELETE para dizer ao SGBD quais linhas serão deletadas.
- E podemos apagar todas as linhas de uma tabela com este comando: DELETE FROM nome_tabela;
SEJA CUIDADOSO AO USAR O DELETE
- Cada vez que você exclui registros em sua tabela, você corre o risco de acidentalmente apagar registros que não tinha a intenção de remover.
- Certifique-se de construir uma cláusula bem precisa no comando WHERE para atingir o alvo exato, ou seja as linhas que realmente deseja apagar.
Tópicos relacionados
- INSERT
- UPDATE
15. Truncar Dados – TRUNCATE TABLE Remova todos os registros de tabelas
Resumo: neste tópico, você vai aprender a instrução SQL chamada TRUNCATE TABLE para remover todos os registros de uma tabela grande no banco de dados de forma eficiente.
Para excluir todos os registros de uma tabela do banco de dados você pode usar o DELETE. No entanto, com uma tabela que tem um grande número de registros, a instrução DELETE não é eficiente. Felizmente, o SQL nos fornece a instrução TRUNCATE TABLE, que você pode usar para remover todos os registros de uma tabela do banco de dados de forma eficiente. A sintaxe do comando TRUNCATE TABLE é a seguinte:
TRUNCATE TABLE tabela_nomeApós a palavra TRUNCATE TABLE é o nome da tabela que deseja remover todos os registros. Ao contrário da instrução DELETE, a instrução TRUNCATE não tem cláusula WHERE.
Vamos praticar a instrução TRUNCATE TABLE para torná-la mais clara.
Primeiro, criamos uma tabela chamada TMP com duas colunas id e nome:
CREATE TABLE `northwind`.`tmp`
(
`id` INT NOT NULL AUTO_INCREMENT ,
`nome` VARCHAR(45) NULL , PRIMARY KEY (`id`)
);Em segundo lugar, inserimos alguns dados de exemplo usando INSERT:
INSERT INTO tmp(nome) VALUES('MySQL');
INSERT INTO tmp(nome) VALUES('PostgreSQL');
INSERT INTO tmp(nome) VALUES('Oracle');
INSERT INTO tmp(nome) VALUES('Microsoft SQL Server')Em terceiro lugar, consultamos através do comando SELECT para testar se as nossas operações de INSERT tiveram efeito.
SELECT * FROM tmp;Finalmente, podemos usar TRUNCATE TABLE para remover todos os registros da tabela TMP. É importante notar que esta é apenas uma demonstração, pois nossa tabela não tem grande número de registros para comparar o desempenho entre DELETE e TRUNCATE TABLE.
TRUNCATE TABLE tmpSe consultar a tabela TMP, novamente, você não vai ver nenhum retorno de dados porque a tabela TMP agora está vazia.
A declaração TRUNCATE tem várias vantagens quando comparada com a instrução DELETE em SGBD, tais como o Microsoft SQL Server, Oracle e MySQL.
- A declaração TRUNCATE TABLE usa menos espaço de log de transações, porque ele exclui todos os registros de uma vez, enquanto o comando DELETE remove uma linha de cada vez e escreve um log de transações para cada registro excluído.
- A declaração TRUNCATE TABLE usa trava de tabela (LOCK), enquanto o comando DELETE usa nível de bloqueiod e linha, portanto, TRUNCATE TABLE usa menos bloqueios do que a instrução DELETE.
- A declaração TRUNCATE TABLE executa mais rápido que o DELETE quando você deseja excluir todos os registros de uma grande tabela.
No entanto, existem algumas limitações de uso da instrução TRUNCATE TABLE:
- A declaração TRUNCATE TABLE não pode ser usada em uma tabela referenciada por uma restrição FOREIGN KEY.
- Em alguns SGBDs, o TRUNCATE não pode ser usado na tabela que participa de um índice ou uma tabela utilizando um cenário de replicação.
É importante notar que, se a tabela que você aplicar o TRUNCATE TABLE tem uma coluna auto-incremento, o contador da coluna irá repor o seu valor inicial definido na definição da coluna, ou seja zerar.
Neste tópico, você aprendeu como usar TRUNCATE TABLE para remover todos os registros de uma tabela de banco de dados.
16. Unir Consultas – UNION
Resumo: Neste tópico, você aprenderá como usar o UNION para combinar resultados de dois ou mais conjuntos de resultados retornados da instrução SELECT.
Existe outra maneira de se obter resultados combinados a partir de duas ou mais tabelas que não seja um JOIN, é um comando chamado UNION (união). A UNIÃO combina os resultados de duas ou mais buscas em uma tabela, com base no que você especificar na lista do SELECT.
No exemplo abaixo três tabelas estão sendo unidas pelo UNION através de três consultas (SELECT), são elas: job_current, job_desired e job_listing. Note que apenas a coluna title está sendo recuperada nos dois selects.
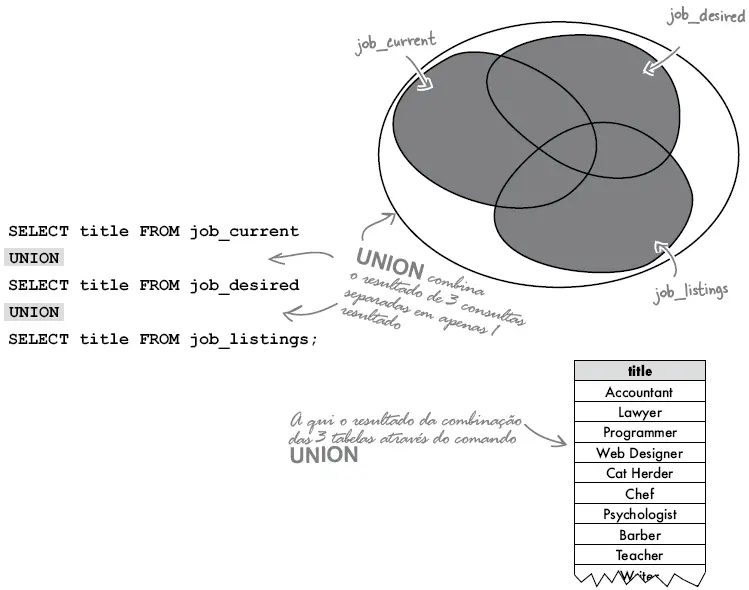
A sintaxe de UNION é a seguinte:
SELECT lista_colunas1 FROM tabela1
UNION (DISTINCT | ALL)
SELECT lista_colunas2 FROM tabela2Basicamente, a primeira e a segunda consulta podem ser qualquer tipo de consulta SELECT com uma restrição. A lista_colunas1 e lista_colunas2 tem que ser compatível. Significa que ambas as listas de colunas devem ter o mesmo número de colunas e cada coluna correspondente deve ser do mesmo tipo de dados, ou pelo menos um tipo de dados que possa sofre conversão.
Por padrão, o UNION elimina todos os registros duplicados. É importante notar que os valores NULL são considerados como um único neste caso. As Palavras-chave ALL e DISTINCT são parte opcional da cláusula UNION. A cláusula ALL permite que você tenha registros duplicados no resultado. Já o DISTINCT elimina registros duplicados e é usado como padrão, não precisando declarar a cláusula DISTINCT.
Vamos dar uma olhada em alguns exemplos do uso do UNION.
Para encontrar as cidade de clientes e fornecedores, podemos obter a cidade dos clientes da tabela de clientes e a cidade dos fornecedores da tabela fornecedores. Em seguida, combinar as duas consultas em um conjunto utilizando o UNION.
SELECT Cidade FROM Clientes
UNION
SELECT Cidade FROM FornecedoresAqui o resultado da consulta:

Se você usar o UNION com a cláusula ALL você vai ver os valores duplicados no resultado:
SELECT Cidade FROM Clientes
UNION ALL
SELECT Cidade FROM Fornecedores
NÃO ESQUEÇA AS REGRAS DO UNION
- O número de colunas em cada declaração do SELECT deve corresponder. Você não pode selecionar duas colunas da primeira declaração e uma a partir da próxima.
- As mesmas funções de agregação devem constar em cada declaração SELECT.
- Você pode colocar os SELECT’s em qualquer ordem, que não irá alterar os resultados.
- Por padrão, o SQL suprime valores duplicado a partir dos resultados de um UNION, para mostra-los utilize a cláusula ALL.
- Os tipos de dados nas colunas precisam ser as mesmas, ou ser conversíveis uns aos outros.
Neste tópico, você aprendeu como usar o UNION para combinar resultados em um conjunto de duas ou mais consultas SELECT.
17. Consultas Complexas – INNER JOIN
Resumo: neste tópico, você vai aprender como obter dados de várias tabelas usando SQL INNER JOIN.
No tópico SELECT, você aprendeu como recuperar dados de uma única tabela. No entanto, na maioria das vezes você vai precisar para recuperar dados de várias tabelas formando registros completos para análise. A cláusula JOIN é a responsável pela junção e recuperação de dados de duas ou mais tabelas. Existem vários tipos de JOINs como: INNER JOIN, RIGHT JOIN, LEFT JOIN, CROSS (FULL) JOIN,e SELF JOIN. Neste tópico, vamos Abordar o INNER JOIN.
INNER JOIN para obter dados de duas tabelas
Um INNER JOIN combina os registros de duas tabelas (ou mais) utilizando uma condição de operadores de comparação. As colunas são retornadas apenas quando as linhas correspondem à condição.
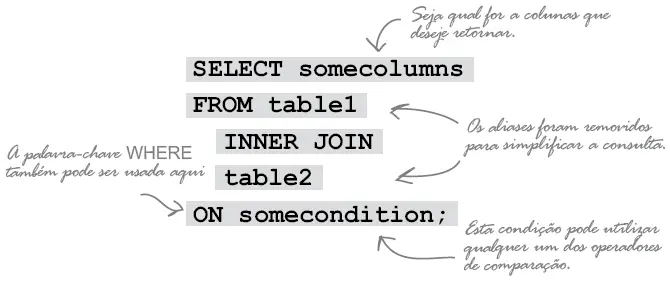
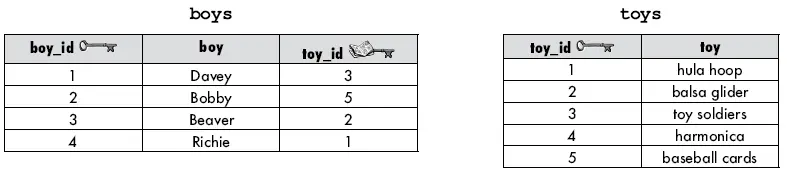
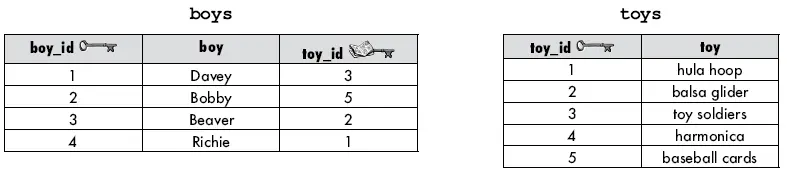
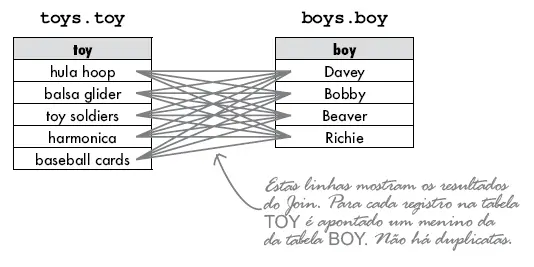
Considere as tabelas abaixo. Cada meninos (boy) tem apenas um brinquedo. Nós temos um relacionamento de 1:1 e toy_id é uma chave estrangeira (lembre-se que este objeto não está normalizado).
Queremos descobrir que brinquedo cada meninos possui. Podemos usar o INNER JOIN com o operador de igualdade ( = ) para combinar a chave estrangeira na tabela meninos com a chave primária em brinquedos (toys) e ver o resultado.
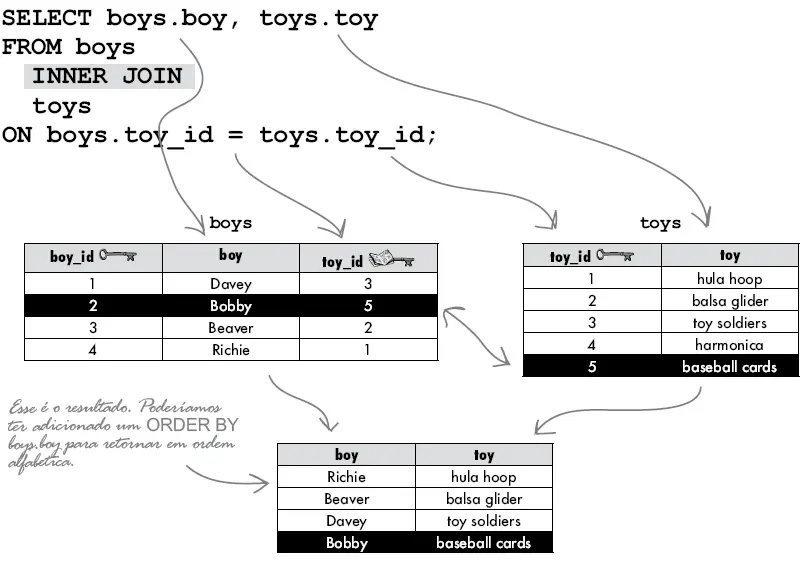
Vamos mostrar outros exemplos para ilustrar as idéias básicas por trás do INNER JOIN. Os exemplos a seguir usam as tabelas Produtos e Categorias. Abaixo o diagrama do banco de dados demonstrando o relacionamento entre as duas tabelas que serão utilizadas.
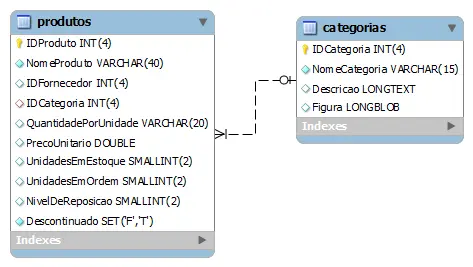
- Uma categoria tem vários produtos
- Um produto pertence a apenas uma categoria
Portanto, a cardinalidade acima é uma relação de um-para-muitos entre as tabelas Categorias e Produtos. A ligação entre Categorias e Produtos é feita através do campo IDCategoria. A exigência é uma combinação de dados de ambas as tabelas para retornar os dados abaixo:
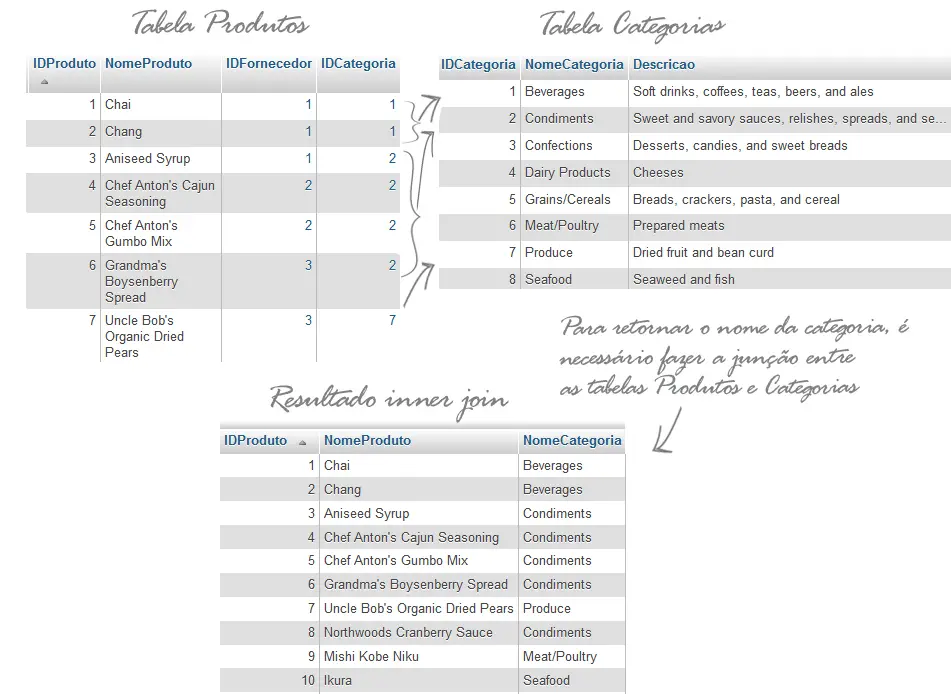
IDProduto, NomeProduto da tabela PRODUTOS
NomeCategoria da tabela CATEGORIASA consulta para obter os dados de ambas as tabelas é da seguinte forma:
SELECT IDProduto,NomeProduto,NomeCategoria
FROM Produtos
INNER JOIN Categorias ON Categorias.IDCategoria = Produtos.IDCategoriaPara cada registro de produto na tabela Produtos, o INNER JOIN encontra um registro de categoria correspondente na tabela de Categorias pois as duas possuem o mesmo IDCategoria que é especificado na cláusula INNER JOIN. Esta expressão também é chamada de condição de junção ou join. Se houver uma correspondência, o SQL retorna o registro, caso contrário, ele verifica um outro registro na tabela de produtos. Este processo continua até que o último registro da tabela de produtos seja verificada.
INNER JOIN implícito
Existe uma outra maneira de utilizar o INNER JOIN, é chamada de implícita como ilustrada abaixo:
SELECT seleção_de_campos
FROM tabela_A, tabela_B
WHERE condição_de_junçãoDa maneira implicita, para chamar o INNER JOIN, especificamos as tabelas a serem unidas após a cláusula FROM e colocamos a condição de junção na cláusula WHERE. Podemos reescrever o exemplo de consulta utilizando INNER JOIN implícito da seguinte forma:
SELECT IDProduto,NomeProduto,NomeCategoria
FROM Produtos, Categorias
WHERE Produtos.IDCategoria = Categorias.IDCategoriaINNER JOIN para obter dados de três tabelas
Podemos usar as mesmas idéias para unir três tabelas ou até mais. Podemos retornar os campos IDProduto, NomeProduto NomeCategoria, e NomeCompanhia uti,lizando a seguinte consulta:
SELECT IDProduto, NomeProduto, NomeCategoria, NomeCompanhia as Fornecedor
FROM Produtos
INNER JOIN Categorias ON Categorias.IDCategoria = Produtos.IDCategoria
INNER JOIN Fornecedores ON Fornecedores.IDFornecedor = Produtos.IDFornecedor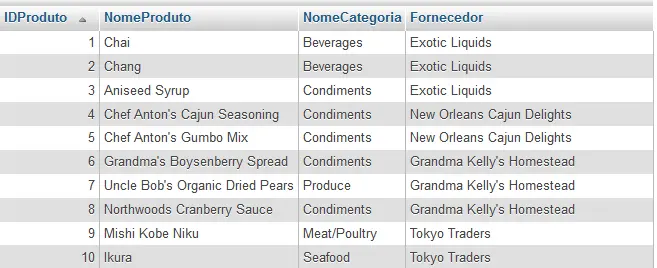
Visualize o INNER JOIN através de conjuntos
O INNER JOIN retorna todos os registros da tabela A(tabela à esquerda), que tem um registro correspondente na tabela B (tabela à direita).

INNER JOIN com a cláusula NOT
O não-equijoin retorna linhas que não são iguais. Considere as tabelas BOYS e TOYS. Ao usar o não-equijoin, podemos ver exatamente quais os brinquedos cada menino não possui (que poderia ser útil caso fosse sobre aniversários dos meninos).
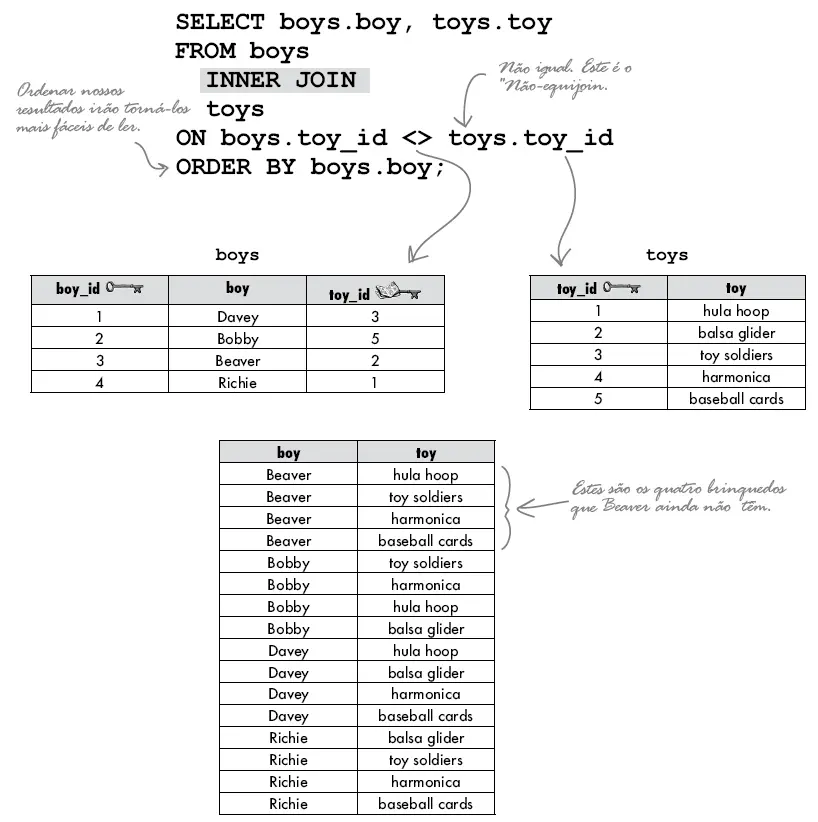
Neste tópico, você aprendeu como usar INNER JOIN para obter dados de duas ou mais tabelas usando condições de junção.
18. Consultas Complexas Correspondentes – OUTER JOIN
Diferente do INNER JOIN, o OUTER JOIN retorna todos os registros de ambas as tabelas associadas ainda que nenhum registro correspondente seja encontrado. Existem três tipos de : FULL OUTER JOIN, LEFT OUTER JOIN e RIGHT OUTER.
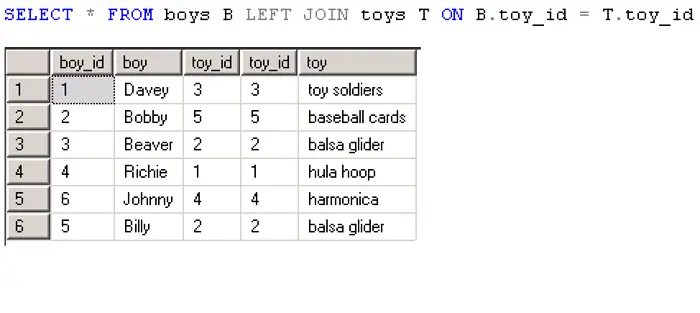
LEFT OUTER JOIN
Suponha querer juntar duas tabelas A e B.O LEFT OUTER JOIN retorna todos os registros da tabela A (tabela à esquerda) mais os registros correspondentes na tabela B (tabela à direita). Isso significa que o resultado do LEFT OUTER JOIN sempre contém os registros da tabela A (lado esquerdo), mesmo sem nenhum registro correspondente encontrada na tabela B, mais os registros correspondentes na tabela B.
Aqui está o diagrama para visualizar o conjunto formado com o LEFT JOIN.
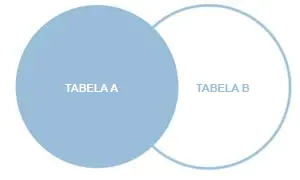
A sintaxe do LEFT OUTER JOIN é a seguinte:
SELECT * FROM tabela_A
LEFT OUTER JOIN tabela_B ON condição_join
WHERE condição_linhas
O LEFT JOIN retornar todas as linhas de uma tabela A (à esquerda), muito embora não haja colunas correspondentes na tabela B.
RIGHT OUTER JOIN
O RIGHT OUTER JOIN retorna todos os registros da tabela B (tabela no lado direito), mesmo sem nenhum registro encontrado na tabela A, além dos registros correspondentes na tabela A.
Diagrama de para visualizar como o RIGHT OUTER JOIN:
A sintaxe de RIGHT OUTER JOIN é como se segue:
- SELECT lista_de_colunas
- FROM tabela_A
- RIGHT OUTER JOIN tabela_B ON condição_join
- WHERE condição_linhas
O RIGHT JOIN mostra somente os dados da tabela que estiver declarada do lado direito a consulta.
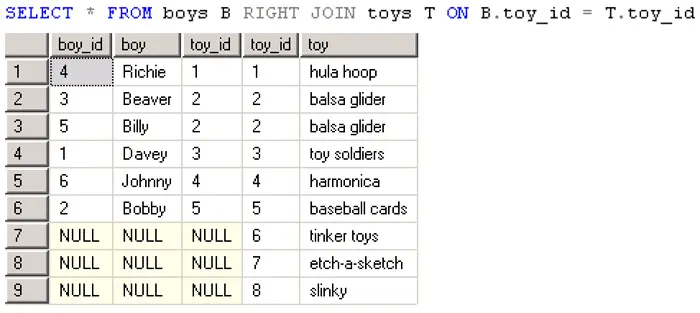
Veja que mesmo sem existir correspondentes na Tabela A, o O RIGHT JOIN trouxe todos os dados da tabela a direita, neste caso a tabela Toys.
FULL OUTER JOIN ou CROSS JOIN
A consulta do tipo FULL ou CROSS JOIN retorna todas as combinações possíveis para cada um dos atributos de cada tabela, portanto, ele retorna todos os registros de ambas as tabelas.Veja abaixo:


O CROSS JOIN acima obtém 20 resultados. Pois a Tabela TOYS possui 5 registros (brinquedos) e a tabela BOYS possui 4 registros (meninos), sendo assim: 5 * 4 = 20. Todas as combinações possíveis.
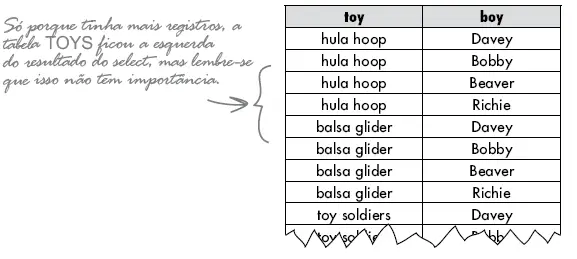
Diagrama para visualizar como o FULL OUTER JOIN funciona:
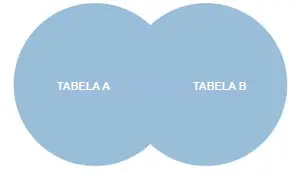
A sintaxe do FULL OUTER JOIN é a seguinte:
SELECT lista_de_colunas
FROM tabela_A
FULL OUTER JOIN tabela_B ON condição_join
WHERE condição_linhasNeste tópico, você aprendeu como utilizar os tipos de OUTER JOINS como: LEFT OUTER JOIN, RIGHT OUTER JOIN e FULL (CROSS) OUTER JOIN.
19. Auto Consultas – SELF JOIN
Resumo: neste tópico, você aprenderá como usar o self-join que é uma junção com a própria tabela.
O self-join é simplesmente uma junção normal que é utilizado para unir uma tabela a ela mesma. O self-join pode ser feito usando alias de tabela para tratar uma tabela como se fosse uma tabela diferente e depois juntá-las. O self-join pode ser utilizado com qualquer tipo de JOIN como: INNER JOIN e OUTER JOIN.
Abaixo a sintaxe do self-join:
SELECT lista_de_colunas
FROM tabela_A AS A
INNER JOIN tabela_A AS B ON A.coluna_nome1 = B.coluna_nome2, ...
WHERE alguma_condiçãoO self-join é muito útil quando você deseja recuperar os dados relacionados com o armazenamento em uma tabela como a estrutura organizacional. Na tabela funcionários que armazena os dados não só dos funcionários, mas também a estrutura organizacional. A coluna Reportase específica o gerente de um empregado que e é referenciada pela coluna IDFuncionario.
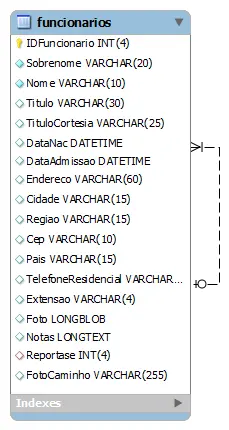
A fim de mostrar quem se reporta a quem, podemos utilizar o self-join da seguinte forma:
SELECT concat(F.nome, F.Sobrenome)Gerente ,concat(G.nome,G.Sobrenome) Funcionario
FROM funcionarios F
INNER JOIN funcionarios G ON F.IDFuncionario = G.ReportaseVeja o conteúdo da Tabela Funcionarios abaixo e repare na coluna Reportase (é o próprio código IDFuncionario):
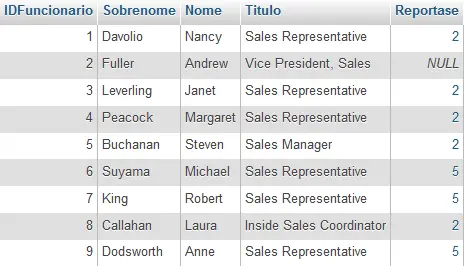
Aqui está o resultado da consulta self-join acima, nota-se que o funcionário Andrew Fuller possui cargo de gerente e tem como subordinados os funcionarios de IDFuncionário: 1, 3, 4, 5 e 8.
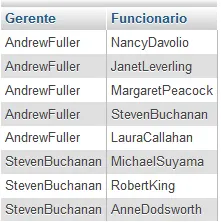
Neste tópico, você aprendeu como usar o self-join para unir uma tabela a ela mesma.
Tópicos relacionados
- INNER JOIN
- OUTER JOIN
- Subqueries
20.Subconsultas – SUBQUERY
Resumo: neste tópico, vamos falar sobre subconsultas e mostrar-lhe como montar subconsultas complexas.
Introdução ao conceito subconsulta
Uma subconsulta é uma consulta regular que está aninhada dentro de outra consulta como SELECT, INSERT, UPDATE ou DELETE. Uma subconsulta retorna um conjunto de resultados e se executa de forma independente. Em seguida, este conjunto de resultados é usado pela consulta contendo a subconsulta.



Combinando as duas consultas em apenas uma consulta com uma subconsulta.
Tudo o que fizemos é combinar as duas consultas em uma. A primeira consulta é conhecida como OUTER QUERY. E a consulta interior é conhecida como INNER QUERY.

Uma subconsulta pode ser utiizada em qualquer SELECT onde uma expressão seja aceita.
Uma subconsulta também pode ser aninhada dentro de outra subconsulta. Os níveis de aninhamento de subconsultas dependem da implementação do SGBD. Por exemplo, Microsoft SQL Server suporta até 32 níveis de subconsultas.
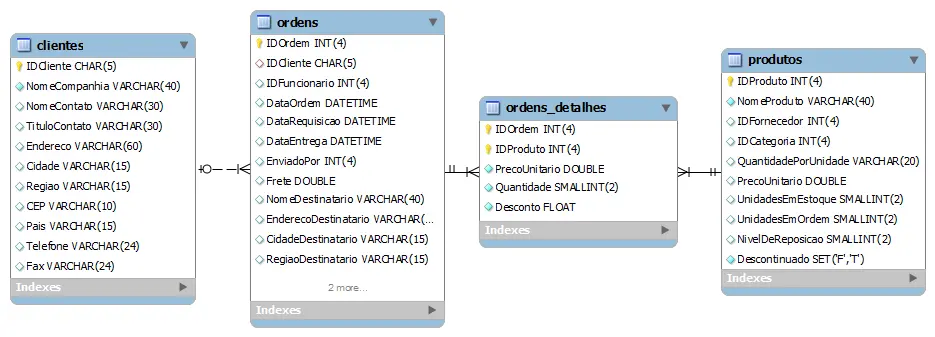
Vamos a alguns exemplos para ilustrar as idéias básicas da subconsulta. Vamos usar o esquema de banco de dados a seguir. O esquema contém quatro tabelas:
- CLIENTES – contém dados dos cliente.
- PRODUTOS – contém dados dos produtos.
- ORDENS – contém os dados dascompra incluindo os clientes que tem ordens.
- ORDENS_DETALHES – contém dados dos itens dos pedidos, incluindo os produtos vendidos.
Exemplos de Subconsulta
Subconsulta com alias de tabela
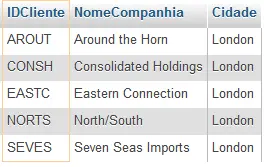
Devemos usar o alias de tabela para a subconsulta que se refere à mesma mesa que consulta externa. Por exemplo, podemos encontrar todos os clientes que localizam na mesma cidade como cliente com ID BSBEV valor usando a consulta abaixo:
SELECT IDCliente,NomeCompanhia,Cidade
FROM Clientes
WHERE IDCliente <> 'BSBEV' AND
Cidade = (SELECT c2.Cidade FROM Clientes AS c2 WHERE c2.IDCliente = 'BSBEV')A subconsulta retorna a cidade onde se localiza os clientes onde o IDCliente seja BSBEV, no caso a cidade de London. Então esta cidade é usada para alimentar a consulta externa para localizar todos os clientes que se localizam na cidade. Ou seja, dentro dos parenteses (inner query) está escrito (London).
Subconsulta com IN e NOT IN
Uma subconsulta com IN ou NOT IN retorna um conjunto de resultados para ser usado pela consulta externa. A inner Query é executada em primeiro Lugar.
A consulta abaixo encontra todos os pedidos encomendados por clientes nos EUA. A subconsulta encontra todas as identificações de clientes nos EUA e este conjunto de resultados é usado para a consulta externa para recuperar as ordens com base nas identificações de clientes. Se executarmos apenas a subconsulta teriamos dentro dos parenteses a seguinte lista: (RATTC, WHITC, SPLIR, RATTC, OLDWHO….etc).
SELECT IDOrdem,IDCliente,NomeDestinatario
FROM Ordens
WHERE IDCliente IN (SELECT IDCliente FROM Clientes WHERE Pais = 'USA')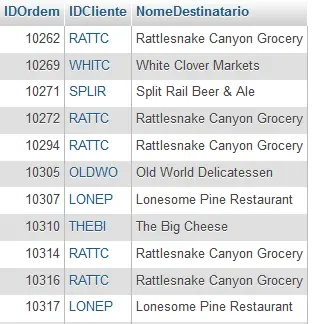
Se usarmos o NOT IN, teríamos todas as encomendas feitas fora dos EUA.
Subconsulta com UPDATE, DELETE e INSERT
Uma subconsulta pode ser aninhada em declarações DML, tais como SELECT, UPDATE, DELETE e INSERT.
Abaixo uma consulta para aumentar o preço unitário em 5% para todos os produtos fornecidos pelo fornecedor de ID 15.
UPDATE Produtos
SET PrecoUnitario = PrecoUnitario * 0.5
WHERE IDProduto IN (SELECT IDProduto FROM Fornecedores WHERE IDFornecedor = 15)Subconsulta utilizada como expressão e formando uma coluna
Uma subconsulta pode ser utilizada para substituir uma expressão em instruções SQL.
Uma subquery pode ser usada como uma das colunas em um SELECT.
A consulta a seguir lista os preços de todos os produtos da categoria bebidas (categoria com valor de id =1), o preço médio dos produtos, e a diferença entre o preço unitário do produto e o preço médio.
SELECT IDProduto,
NomeProduto,
(SELECT AVG(PrecoUnitario) FROM Produtos) AS "Preço Médio",
(PrecoUnitario - (SELECT AVG(PrecoUnitario) FROM Produtos)) AS diferença
FROM Produtos
WHERE IDCategoria = 1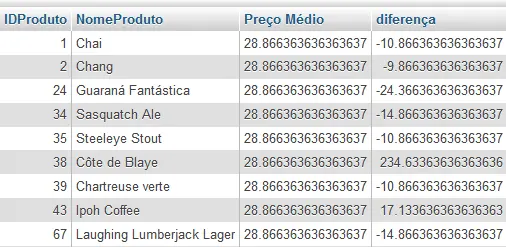
SQL subconsulta com EXISTS e NOT EXISTS
Uma subconsulta pode ser usado para testar a existência de registos. Uma subconsulta neste caso retorna verdadeiro ou falso e seu resultado é usado pela cláusula WHERE da consulta externa.
Neste tópico, nós introduzimos os conceitos de subconsulta com vários exemplos. Compreender e utilizar adequadamente uma subconsulta é crucial para evitar o uso de tabelsa temporárias ao consultar dados em situações complicadas.
Tópicos relacionados
- SELECT
- WHERE
- Alias
- IN
- BETWEEN
- LIKE
- SELF-JOIN
- INSERT
- UPDATE
- DELETE
21.Subconsultas Correlacionadas – SUBQUERYS
Resumo: neste tópico, você vai aprender sobre subconsultas correlacionadas.
O que é Subconsulta correlacionada
Uma subconsulta correlacionada é uma subconsulta que depende da consulta externa. Isso significa que a cláusula WHERE da subconsulta correlacionada utiliza valores da consulta externa. Esta é uma diferença importante entre uma subconsulta correlacionada e uma subconsulta simples. Você não pode executar a subconsulta correlacionada de forma independente, como uma subconsulta simples. Uma subconsulta correlacionada é executada uma vez para cada registro selecionado pela consulta externa.
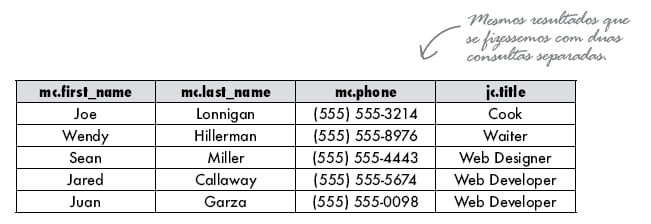
Veja no exemplo abaixo que na cláusula WHERE a comparação entre zip_code acontece entre colunas que estão uma na INNER QUERY e outra na OUTER QUERY, entre as tabelas my_contacts (mc) e state.

Exemplos de Subconsulta Correlacionadas
Vamos dar uma olhada em vários exemplo para entender a idéia básica por trás de uma subconsulta correlacionada.
No exemplo abaixo, vamos encontrar os cinco principais clientes por vendas.
SELECT NomeCompanhia, Cidade,
(SELECT sum(Precounitario * Quantidade)
FROM Ordens
INNER JOIN Ordens_detalhes ON Ordens_detalhes.IDOrdem = Ordens.IDOrdem
WHERE Ordens.IDCliente = Clientes.IDCliente ) AS total
FROM Clientes ORDER BY total DESC LIMIT 5A subconsulta correlacionada calcula as vendas totais para cada cliente selecionado da tabela de clientes. O IDCliente selecionado a partir da consulta externa é passado para a subconsulta correlacionada para o cálculo do total de vendas.
Aqui está o resultado da consulta acima:
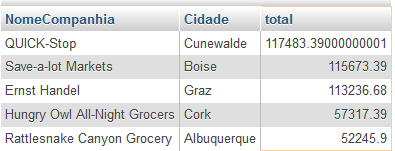
Podemos utilizar subconsulta correlacionada na cláusula WHERE também. Aqui está um exemplo de como usar uma subconsulta correlacionada na cláusula WHERE para localizar todos os clientes que têm no total de vendas mais que 100 mil:
SELECT NomeCompanhia, Cidade
FROM Clientes
WHERE 100000 <
( SELECT sum(Precounitario * Quantidade)
FROM Ordens INNER JOIN Ordens_detalhes ON Ordens_detalhes.IDOrdem = Ordens.IDOrdem
WHERE Ordens.IDCliente = Clientes.IDCliente )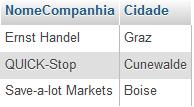
Para cada cliente, a subconsulta correlacionada calcula o total de vendas com base nas ordens. Na cláusula WHERE, se os retornos totais de vendas da subconsulta correlacionada é maior que 100 mil, a consulta vai retornar o cliente.
Neste tópico, você aprendeu o que é uma subconsulta correlacionada e como ela é diferente de uma subconsulta simples. Esperamos que agora você tenha uma melhor compreensão da subconsulta correlacionada para aplicá-la de forma eficaz no trabalho de programação.
Tutoriais relacionados
- ORDER BY
- HAVING
- INNER JOIN
- Subquery
Perguntas Frequentes
DML (Data Manipulation Language) é uma sigla em inglês que significa “Linguagem de Manipulação de Dados”. No contexto de bancos de dados, DML refere-se a um conjunto de comandos utilizados para inserir, atualizar, recuperar e excluir dados de um banco de dados.
Ela inclui comandos como INSERT (inserir), UPDATE (atualizar), DELETE (excluir) e SELECT (recuperar), que são usados para adicionar, modificar, remover e consultar registros em tabelas do banco de dados.
INSERT: Utilizado para adicionar novos registros em uma tabela do banco de dados. UPDATE: Permite modificar os valores de um ou mais registros em uma tabela. DELETE: Utilizado para excluir registros de uma tabela. SELECT: Permite recuperar os dados armazenados em uma tabela, seja retornando todos os registros ou uma seleção específica com base em condições.






